Pár pohledů do historie a základní principy
Pevné disky jsou založeny na principu magnetického záznamu, který je znám už pěkných pár desítek let (drátofony, magnetofony, video, datové pásky, diskety...). V podstatě jde o to, že máme kus tvrdého feromagnetického materiálu (FeOx, FeNiCr, tvrdé ferity), který si po zmagnetování indukční cívkou, kdy se orientují domény materiálu ve směru magnetického pole, udrží svou orientaci dlouho i po zániku pole. Snímací cívkou pak lze (opakovaně) zjistit jak byl materiál magnetován a získat tak zpět zaznamenanou informaci. Magnetický záznam je mazatelný, a to dvěma způsoby. Buď vystavením globálnímu střídavému nebo stejnosměrnému magnetickému poli, které zruší různou orientaci domén nebo je všechny orientuje jedním směrem. A nebo vystavením Curieově teplotě (záleží na materiálu, typicky několik set °C), při které dojde ke spontánnímu odmagnetování. Tuto možnost využívají magneto-optické disky.Nejjednodušší praktické využití je v podobě magnetického pásku, jenž se převíjí mezi dvěma cívkami a je magnetován a snímán dvěma statickými magnetickými hlavami (cívka se vzduchovou mezerou, kterou mag. pole vystupuje/vstupuje do pásku). Pro využití ve výpočetní technice má však zásadní nevýhodu - rychlost přístupu k náhodně vybraným datům je velmi dlouhá (převíjení pásku trvá řádově minuty). Využívá se tedy pouze pro účely zálohování, kde se zapisují a čtou veliké souvislé bloky dat (moderní pásky dosahují kapacit až TB).
Proto bylo vymyšleno nové, zcela odlišné uspořádání. Magnetické záznamové médium v podobě kruhového rotujícího disku nad nímž se pohybují hlavy. U disket (floppy disk=pružný disk) je nosným materiálem plastový kotouč s magnetickou vrstvou po kterém se přímo šoupou hlavy z obou stran média čímž dochází k opotřebení až vydření povrchu a vzniku vadných míst. Naproti tomu u harddisků je použito kovových (nějaká slitina Al) kotoučů (ploten) s magnetickou vrstvou nad níž se hlavy vznáší ve výšce řádu mikrometrů na vzduchovém polštáři. Proto není dobré do disku za chodu moc mlátit, aby si hlava nesedla na povrch... V prašném prostředí zas může kolizi způsobit částečka prachu/kouře, která se dostala dovnitř skrz prachový filtr. Stejně tak by asi běžný disk nefungoval ve vakuu.
Toto nové uspořádání kladlo výrazně vyšší nároky na jemnost magnetické vrstvy a miniaturizaci hlav, protože její plocha byla mnohem menší než plocha pásku. Celková plocha se dá zvětšit tím, že se na jednu hřídel navlíkne více kotoučů, kde každý má svůj pár hlav. Hlavy jsou umístěné na ramínkách a pohybují se všechny součastně od kraje ke středu po určitých pevně daných krocích. Pro každý krok si můžeme představit jak hlava opisuje na plotně kružnici určitého průměru - stopu. Souhrn všech kružnic na jednotlivých plotnách stejného průměru tvoří tzv. cylindr = válec (čísluje se od 0). Konkrétní kružnice je určena číslem hlavy (čísluje se též od 0). Každá kružnice je pak dále rozdělena na sektory (čísluje se od 1) pevně dané velikosti (typicky 512 B). Tím byl položen základ tzv. CHS (Cylinder/Head/Sector) diskové geometrii, která jednoznačně určuje dané místo na disku. Více napoví obrázek:
 |
V knize Václav Šedý - Rozeberte si PC jsem se dočetl o zajímavém experimentu, jak jednoduše v domácích podmínkách zviditelnit magnetický záznam na plotně disku, disketě či magnetické kartě. Na HDD jsou jednotlivé bity na pozorování pouhým okem příliš malé, ale zřetelně lze rozeznat značky začátků sektorů a u disků s malou hustotou i stopy. Asi si vzpomenete na pokus z fyziky s magnetem a železnými pilinami na papíře, které zobrazí magnetické siločáry. Na miniaturní magnetické domény na plotně disku je však potřeba trochu jemnější kalibr - feritový prášek. K jeho výrobě budeme potřebovat jemný brusný papír (já jsem měl po ruce 800) a nějaké feritové jádro z nepotřebné cívečky nebo tráfka. Na brusný papír nalejeme trochu piva (zřejmě autorův oblíbený nápoj ;) a brousíme na něm jádro. Občas odlejeme vzniklé "blátíčko" do sklenky a pokračujeme. Nakonec vzniklou břečku ještě trochu rozředíme pivem, promícháme a necháme pár minut odstát (usadí se ty nejtěžší částice). Pak to nalijeme na plotnu disku, kterou mírně nakláníme sem a tam, aby se feritové částečky všude dostaly. Během chvilky by se měly objevit na plotně značky sektorů jako na obrázku níže. Po zaschnutí by měl zůstat obrazec fixovaný díky obsaženému cukru, ale už to nevypadá tak pěkně. Já jsem experimentoval s několika plotnami z HDD, magnetickou identifikační kartou do práce, magnetickým štítkem do starého počítače HP a 8" disketou. Nejlépe dopadly fotky plotny z 2,5" HDD Conner CP-2064 (64 MB na 2 plotnách), jen škoda, že nemám mikroskop.
 |
Harddisky ST506/ST412 (MFM, RLL)
Tyto pevné disky byly první, které se objevily v původním IBM PC-XT. Zabíraly 1 - 2 pozice 5,25" (později i jen 1x 3,5") a dosahovaly kapacit typicky 10 - 80 MB. Pomocí jednoho standardního řadiče bylo možno připojit 1 nebo 2 disky. Rozhraní disku se sestávalo z napájecího, datového a řídicího konektoru. Proto aby PC-XT vůbec mohl disky využít, měl řadič na sobě svůj vlastní BIOS, který po inicializaci nainstaloval služby přerušení INT13h, které pak mohl volat DOS. BIOS také někdy obsahoval utilitu na low-level formátováni disku, kterou bylo možno spustit z DOSu příkazem debug -g D000:3, kde D000 byl typicky segment HDD BIOSu.Tyto disky nedisponovaly téměř žádnou inteligencí, ovládání probíhalo zhruba tak, že se nakrokovala pozice cylindru (používal se krokový motor), dalšími dráty se vybrala hlava, počkalo se až se příslušný sektor objeví pod hlavou a pak se sektor zapsal/přečetl. Počet sektorů na stopu byl konstantní, takže kraje plotny byly méně využité začátek. U těchto disků bylo typické, že občas už od výroby obsahovaly pár vadných sektorů, které byly vypsány na nálepce na krytu a zadávaly se při low-level formátu a tím se úplně vyřadily z používání. Low-level formát se také používal pro obnovení značek začátků sektorů a pro nastavení tzv. interleavingu. Při čtení disk totiž nebyl schopen tak rychle číst ihned po sobě následující sektory, takže by se muselo na další skoro celou otáčku čekat. Proto se pořadí sektorů na stopě proházelo tak, aby sekvenční čtení bylo rychlejší. Pokud se mělo s diskem nebo s celým PC nějak manipulovat, bylo nutno ručně pomocí programu zaparkovat hlavy mimo aktivní oblast, aby nedošlo k mechanickému poškození. Zde je typický představitel MFM disků Seagate ST-225 s kapacitou 20 MB (BTW dodnes funkční) a MFM řadič DTC 5150CI do 8-bitové ISA sběrnice:
 |
 |
 |
Harddisky IDE (Integrated Device Electronic) 1. generace
Staly se nejrozšířenější náhradou MFM disků pro stolní PC. Na serverech se spíše prosazovalo rozhraní ESDI, ze kterého pak vzešlo SCSI, které ale bylo mnohem dražší a tak se na běžných PC moc neuchytilo. Idea IDE byla integrovat na diskovou jednotku více elektroniky, která umožní ovládání pomocí standardizované sady příkazů ATA. Rozhraní vzniklo zjednodušením stávající sběrnice ISA a proto také název AT-bus, ATA - AT Attachment. Dodnes přetrvalo v podobě dvouřadého 40-ti pinového konektoru. Řadiče IDE byly zpočátku na samostatných kartách a zhruba od konce éry 486 a počátkem éry Pentií se začaly běžně integrovat na základní desku. Dnes máme k dispozici obvykle 2-4 IDE kanály, na každém kanálu mohou být až 2 jednotky (master, slave).Změnila se také metoda záznamu dat na ZBR (Zone Bit Recording), která už nemá konstantní počet sektorů na stopu a tak došlo k lepšímu využití povrchu. Pro kompatabilitu je však stanoven nějaký papírový pevný počet sektorů na stopu, které si pak elektronika disku sama přebere. Zpočátku se pro přenos dat používaly různé režimy PIO, tedy přes I/O porty, což zatěžovalo CPU a limitovalo rychlost. Používání IDE disků také usnadnila funkce autodetekce, kdy si disk nese informaci o své geometrii, takže už není třeba si tyto údaje psát někam na papír (samozřejmě pokud to umí BIOS přečíst). Objevuje se zde také první problém s kapacitním limitem na 504 MB. Z různých omezení řadičem a BIOSem (parametry služeb INT13h) vyplývá, že disk může mít max. 1024 cylindrů, 16 hlav a 63 sektorů na stopu, tedy celkem 1024*16*63*512 = 528482304 B. Pevný disk IDE Conner CP-30084 s kapacitou 84 MB:
 |
Harddisky EIDE 2. generace
Problémy s rostoucí kapacitou bylo třeba nějak nějak řešit. Zavedla se proto translace geometrie a později LBA. Translace se začala používat už dříve, aby se BIOSu nabulíkoval počet cylindrů 1024 a méně a na úkor toho se zas zvětšil počet hlav. Např. jednotka, která měla fyzicky CHS = 1600/4/63 se tvářila jako 800/8/63, čímž se počet cylindrů dostal pod 1024 a BIOS byl spokojen. Tedy až do té doby, než se vyčerpal limit pro počet hlav 256. A tak vznikl další limit BIOSu 8,4 GB 1024*256*63*512 = 8455716864 B (služby BIOSu INT13h používají pro přenos CHS parametrů tři 8-mi bitové registry CH, CL a DH).Výrobci si postupně uvědomili, že CHS geometrie už nemá v příliš smysl (zbytečná několikanásobná translace mezi vrstvami APLIKACE-OS-BIOS-DISK) a přešlo se k LBA (Logical Block Addressing). LBA používá lineární adresování, kdy se prostě sektory číslují od nultého do posledního (např. SCSI využívá tento princip od samého začátku). Služby BIOSu INT13h byly rozšířeny o LBA ekvivalentní funkce s čísly 4xh (INT13h extensions). Ty však umí využít až novější OS, např. MS-DOS 7.0 a vyšší, FreeDOS, Windows NT/2K/XP, Linux... Také se přešlo postupně od pomalého přenosu PIO, k režimu Multi Word DMA a Ultra DMA, kdy se přenáší větší blok dat bez přímé účasti CPU do paměti. Pevný disk EIDE disk Western Digital WDAC33100 s kapacitou 3,1 GB (svého času zakoupen za 10500,- Kč) a VLBus EIDE řadič Tekram TRM680C s hardwarovou cache:
 |
 |
Harddisky EIDE 3. generace
Kdo si myslel, že už se problémy s kapacitou vyřešily s pomocí LBA, tak se mýlí. Standardní EIDE řadiče totiž používají pro LBA adresaci 28bitů (3 a 1/2 8bit I/O portu), takže tu máme další limit: 228*512 = 137438953472 B (128 GB). Zpočátku se to zdálo být hodně daleko, ale zvyšování hustoty dat na plochu roste takovým tempem, že před nedávnem padl i tento limit. Jen tak mimochodem, při dnešní běžné hustotě 80GB/plotnu to znamená že jeden bit zabírá plochu menší než 0,015 µm2. Specifikace ATA/ATAPI-6 tedy zavedla nový standard LBA se 48-bit adresováním, které má limit někde na 131072 TB. Tak jsem zvědav, za jak dlouho se to zas bude muset řešit. Pro využití 48-bit LBA je potřeba novější BIOS s updatovanými INT13h extensions (EDD). Do Windows XP je třeba nainstalovat SP1, do Windows 2000 SP3. Pro Windows 98 existují nějaké neoficiální patche, v případě chipsetů intel 8xx a vyšších je k dispozici přímo aktualizovaný ovladač řadiče (balík intel Application Accelerator).Aby čachrů kolem kapacit nebylo málo, dohodli se výrobci disků, že pro označení kapacit budou používat dekadické násobky Byte. Tedy jejich 1 GB = 1000000000 B, zatím co všude jinde znamená 1 GB = 230 = 1073741824 B. Pak se nelze divit, že zakoupený 120GB disk se hlásí po naformátování jen jako 114GB. Trochu mě ale zaráží, že toto značení převzali i výrobci CompactFlash karet (CF je kompatabilní s IDE, pomocí příslušné redukce ji lze používat normálně jako harddisk, tak se holt výrobci CF výrobcům HDD ochotně přizpůsobili). Aby se to značení nějak rozlišilo, navrhla IEC nový standard 60027-2, který označuje binární násobky jako kiB, MiB, GiB...(jako Giga binary Byte) a dekadické jako kB, MB, GB. Pevný disk Seagate Barracuda ST3210026A s kapacitou 120 GB:
 |
Podívejme se nyní podrobněji na některé další vymoženosti moderních disků:
Ultra DMA
S tím jak roste hustota dat na plotnu, tak automaticky roste i přenosová rychlost, aniž by bylo potřeba zvyšovat otáčky (dlouho bylo standardem 5400 RPM, dnes se přešlo na 7200 RPM a nejrychlejší disk, co jsem četl, má 15000 RPM). Aby se však rychlost skutečně využila, specifikovala ATA několik přenosových standardů Ultra DMA 0-6, kterým odpovídají tyto teoretické maximální rychlosti: 0 - 16 MB/s, 1 - 25 MB/s, 2 - 33 MB/s, 3 - 44 MB/s, 4 - 66 MB/s, 5 - 100 MB/s a 6 - 133 MB/s. Je třeba si uvědomit, že maximální propustnost 32bit PCI sběrnice na 33 MHz je taky 133 MB/s. Ale zatím jsem neviděl žádný EIDE disk, který by se přenosovou rychlostí k této hranici blížil.S rostoucí rychlostí rozhraní bylo třeba důrazněji potlačit přeslechy mezi signálovými vodiči IDE kabelu a proto se pro Ultra DMA 3 a vyšší začal používat 80-ti žilový kabel, který vkládá mezi všechny vodiče oddělovací země. Délka kabelu by neměla přesáhnout asi 0,5m. Proto mě trochu překvapuje, že si lidé kabely rozřezávají na nudličky. Sice je kabel ohebnější a zabere míň místa, ale na druhou stranu přece musí mít o něco horší vlastnosti. Otázka je, jak a nakolik je to kritické. Samo rozhraní je totiž zabezpečeno ECC kódem, který chyby automaticky opravuje, ale při přílišném nárůstu chyb by asi došlo ke zpomalení (vlivem opakovaných přenosů) nebo až nefunkčnosti. Jiná věc sou profi vyrobené kablíky, které používají kroucené páry.
Pokud tedy chceme vyšší Ultra DMA režimy využít, je potřeba aby daný mód podporoval samotný disk (což obvykle není problém), abychom měli 80-ti žilový kabel a aby daný mód podporoval řadič. Bohužel v minulosti řadiče za disky dost pokulhávaly. Široce používaný intel 82371 (PIIX4) zvládal jen UDMA33, proto výrobci lepších desek přidávali další řadič (obvykle od firem HighPoint - HPT36x, 37x nebo Promise), který zvládal UDMA66 - UDMA133. Intel přidal podporu UDMA66 v 82801AA (ICH), UDMA100 v 82801BA (ICH-2) a UDMA133 zatím není ani v ICH6 (a nejspíš nebude, protože intel se orientuje hlavně na Serial ATA (150 MB/s)).
Pevný disk je obvykle od výrobce nastaven na UDMA66/100 asi podle toho, co zrovna frčí. Není ovšem od věci si zkontrolovat speciální utilitou od výrobce na jakém UDMA režimu vlastně disk běží. V případě že máte starší řadič, je nanejvýš vhodné nastavit ručně nižší, ještě podporovaný režim. Zde je DLGUDMA pro disky Western Digital a UATA100 pro disky Seagate. Takhle vypadá DLGUDMA v akci (mám nastaven nejvyšší možný režim UDMA100):
S.M.A.R.T.
Tato zkratka znamená Self Monitoring Analysys and Reporting Technology, tedy něco jako technologie pro sebe-monitorování a kontrolu. Během vývoje se EIDE jednotky staly poměrně inteligentní a disponují spousty funkcí, které přímo nesouvisí s ukládáním a čtením uživatelských dat. Technologie S.M.A.R.T. byla vymyšlena za účelem předcházení selhání disku a byla zahrnuta do specifikace ATA/ATAPI-3. Statistiky říkají, že pomocí S.M.A.R.T. lze asi ve 40% úspěšně předejít havárii disku. V podstatě lze selhání rozdělit na dva typy: 1) "náhlá smrt", kdy např. vlivem teplotního šoku odejde elektronika a 2) pozvolná, sledovatelná a předvídatelná degradace některých parametrů. S.M.A.R.T. může tedy pomoci pouze v druhém případě.V podstatě jde o to, že disk trvale sleduje a zaznamenává různé parametry (přímo na disk nebo do EEPROM), během nečinnosti navíc může sám provádět skenování povrchu a při překročení výrobcem nastavených prahových hodnot vydá varovné hlášení. Disk ovšem na vás sám nezakřičí, je třeba použít nějaký software k přečtení S.M.A.R.T. statistik. Bohužel tato funkce není v dnešních operačních systémech běžně k dispozici. Většina nových BIOSů akorát kontroluje S.M.A.R.T. status během POST (po zapnutí a HW resetu) a v případě problémů by se měla objevit nějaká hláška typu "S.M.A.R.T. status invalid".
Pokud si tedy chceme statistiku prohlédnout, je potřeba použít nějaký specializovaný program. Pro Windows 9X/NT/2K/XP se např. hodí SpeedFan, který také zobrazuje údaje HW monitoru/teploměru na základní desce a další. Získaná data vypadají nějak takto:
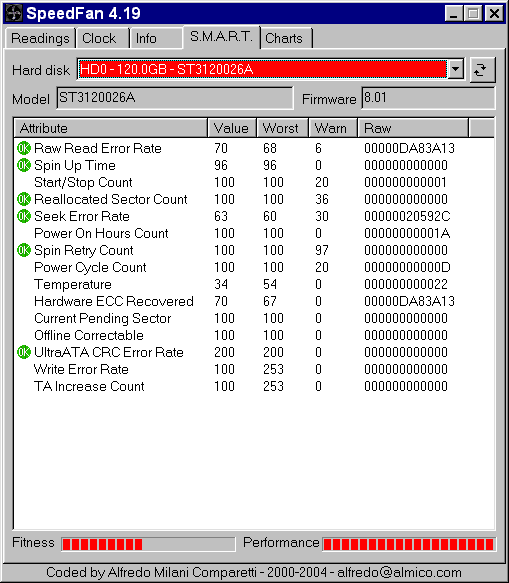
Podivně vypadá vysoká hodnota položky Raw Read Error Rate, která je typická pro disky Seagate (u WD400EB je na 0), nicméně hlásí, že všechny chyby byly opraveny ECC. Tak nevím co si o tom mám myslet. Vzhledem k tomu, že se takto disk projevuje už od prvního zapnutí, a nejen mě, tak to asi bude 'normální'. Reallocated Sector Count udává počet vadných sektorů, které self-test odhalil a přemapoval je do rezervní oblasti. Ano, nové disky už automaticky počítají s možností vytváření 'badbloků' a mají proto určitou rezervovanou oblast, ze které vadné sektory nahrazují. To je prováděno diskovou jednotkou zcela transparentně, takže se vám při scandisku žádný badblok nezobrazí a disk se tváří i nadále bez chyb, jen tato hodnota postupně narůstá. Na svém WD400EB mám takto realokované 2 sektory, bohužel nevím, jestli už od koupi nebo až časem (dříve jsem neměl znalosti ani nástroje abych mohl S.M.A.R.T. monitorovat). Power On Hours Count udává celkový počet hodin, po které byl disk v provozu. Zde má najeto teprve 26hod. Temperature - teplota disku, objevila se až u novějších typů (WD400EB neumí). Důležitá je zejména její maximální hodnota. Výrobci běžně udávají maximální provozní teplotu 60°C, takže pokud na reklamaci uvidí víc, máte automaticky smůlu (pokud tam teda nejsou úplný trubky). Mě se těch poměrně vysokých 54°C podařilo celkem snadno dosáhnout asi po půl hodině v šuplíku, kdy sem měl otevřenou bočnici case, čímž šuplíkem vůbec neprovíval žádný vzduch. Jinak má můj disk běžně kolem 32°C. UltraATA CRC Error Rate udává zřejmě chyby přenosu mezi diskem a řadičem, takže pokud je tam nějaké větší numero, tak by bylo asi třeba zkontrolovat kabel. Proužky Fittness a Performance si nějakým způsobem cucá SpeedFan z prstu, takže na ně neberu moc zřetel.
Pro Linux existuje balík smartmontools, který obsahuje démona smartd a ovládací program smartctl. Poskytuje nejrozsáhlejší statistiky a nejvíce funkcí z toho, co jsem zatím zkoušel. Lze doporučit například pro servery. Pokud vás zajímá hlavně teplota disku, tak se víc hodí program hddtemp.
Pro DOS toho moc není, našel jsem jediný program SMARTUDM. U SpeedFanu a dalších programů pro Windows jsem ale tvrdě narazil na problém, když jsem disky přepojil na druhý řadič HPT370 (UDMA100). Ovladač tohoto řadiče se chová poněkud nestandardně, snaží se emulovat SCSI a příkazy na čtení S.M.A.R.T. zatvrzele odmítá. Zatím jsem nenašel žádný windowsácký program, který by to nějak prostřelil, zřejmě kvůli tomu, že všechny programy spoléhají právě na ne dobře funkční ovladač a API funkce. Pod Windows 9x se to dá snadno obejít přímým přístupem k řadiči (který se jinak chová jako každý normální IDE řadič, pouze sídlí na jiném I/O portu), ale pod Windows NT/2K/XP je to problém, protože mě přímo na železo nepustí.
Protože mě to zajímalo, pustil jsem se do programování vlastního IDE & S.M.A.R.T. info programu. Po pročtení části ATA/ATAPI-7 specifikace (která má BTW přes 1000 stran), jsem zjistil, že přečtení S.M.A.R.T. není zas tak obtížné. Vysláním ATA příkazu B0h s podpříkazem D0h disk vrátí 512B dat aktuálních hodnot (podpříkaz D1h vrací prahové hodnoty). V dokumentaci je popsaná odpovídající struktura. Ta obsahuje až 30 S.M.A.R.T. atributů, které jsou označeny 8bit ID. Každý disk může podporovat různý počet a typ atributů, celkem jich může být až 255. Některé byli popsány výše, celkem jich znám asi 40. Jsou mezi nimi i např. aktuální výška hlav nad povrchem nebo údaje z otřesového senzoru... S.M.A.R.T. a IDE info je nyní zabudované v mém programu SMB 1.18 a spouští se parametrem /IDE. Funguje dobře v DOSu a Windows 9X, ale pod NT spadne, protože mi NT nedovolí zakázat na chvilku přerušení, abych mohl bez kolizí přečíst data z řadiče. Když jsem instrukce CLI/STI odstranil, tak při pouhém čtení z portu řadiče HPT370 na mě Windows hodí BSOD a konec. Nejsem windows programátor, takže nevím jakým trikem to ochcat, no pokud by někdo náhodou věděl, tak se nechám rád poučit. Zde je ukázka výpisu pro můj 1. disk:
SMBus Communication Program 1.18 (C) 2001-2005 by Martin Rehak; rayer^seznam*cz Compiled by GCC 3.4.3 at 12:33:53, Mar 6 2005 (DOS/Win9X compatability) Designed for motherboards with southbridge i82371(PIIX4) or i82801(ICHx) only! i82371 (PIIX4/E) IDE BusMaster controller detected as PCI#0 device 7 h Vendor ID: 8086 h Device ID: 7111 h Controller revision ID: 1 h BusMaster base address: F000 h Primary IDE base address: 1F0 h Secondary IDE base address: 170 h Detecting channel: primary, secondary HPT370 IDE-Raid controller detected as PCI#0 device 13 h Vendor ID: 1103 h Device ID: 4 h Controller revision ID: 3 h BusMaster base address: E000 h Primary IDE base address: D000 h Secondary IDE base address: D800 h Detecting channel: tertiary*, quaternary* Primary master IDE/ATA non-removable drive info [OK]: Drive Geometry (C/H/S): 232581/16/63 (LBA sect. 234441648), size = 120034 MB Drive Model: ST3120026A, S/N: 5JT4A8WK Drive FirmWare: 8.01, Cache Buffer: 8192 kB, enabled, look-ahead Max. Block Transfer: 16 sectors/IRQ, ECC: 4 B, DMA, LBA Minimum MultiWord DMA/PIO/PIO&IORDY cycle time: 120 ns / 240 ns / 120 ns Current Transfer Mode: Ultra DMA 5 (100 MB/s), max. supported Ultra DMA 6 AAM: unsupported, disabled (current/vendor's default: 0/128) APM: unsupported, disabled (current APM level: 254) Security: supported, disabled, unlocked, level = high, Master PWD_RC = FFFE h Security Erase: unsupported Other Features: packed commands = no, 48bit addressing, download uCode S.M.A.R.T: supported, enabled, self-test, error-logging S.M.A.R.T. data rev. 10; 15 valid attributes found, ckecksum: OK ---- ATTRIBUTE NAME ---- VALUE - WORST - THRS ---- RAW --- (* IniVal. ! PFail.) Raw Read Error Rate: 66 / 62 / 6 / 147407968 Spin-up Time: 98 / 96 / 0 / 0 Start/Stop Count: 100* / 100* / 20 / 21 Reallocated Sector Count: 100* / 100* / 36 / 0 Seek Error Rate: 77 / 60 / 30 / 57364351 Power-on Hours Count: 99 / 99 / 0 / 880 (36.67 days) Spin-up Retry Count: 100* / 100* / 97 / 0 Start/Stop Cycle Count: 100* / 100* / 20 / 435 (11.86x/day) Drive Temperature: 34 / 57 / 0 / 34 °C Hardware ECC Recovered: 66 / 62 / 0 / 147407968 Current Pending Sect.Cnt: 100* / 100* / 0 / 0 Off-line Scan Uncorr.Cnt: 100* / 100* / 0 / 0 UltraDMA CRC Error Rate: 200 / 200 / 0 / 0 Write Error Rate: 100* / 253 / 0 / 0 Data Addr. Mark Errors: 100* / 253 / 0 / 0 |
S.M.A.R.T. self-test
Někdy když mámě podezření, že není s diskem něco v pořádku, může být dobré vyvolat S.M.A.R.T. self-test explicitně a prohlédnout si výsledky. Výrobci disků obvykle dodávají nějakou testovací utilitu, která to umožní. Někdy lze ještě vybrat jestli má být test rychlý nebo podrobný. U WD400EB trvá rychlý test asi 3min a podrobný asi 20min. Zde je Data Life Guard pro disky Western Digital (bootovací disketa pro DOS) a SeaTools pro disky Seagate (bootovací ISO image). Pokud test narazí na chybu, tak neváhejte disk reklamovat. Takhle vypadá DLG v akci (při quicktestu):
AAM - Automatic Acoustic Management
AAM je další zajímavá fíčura zahrnutá do specifikace ATA/ATAPI-6. Umožňuje uživateli vybrat si kompromis mezi hlukem, který vydávají hlavy při seeku a výkonem (resp. průměrnou přístupovou dobou). Defaultní hodnota od výrobce bývá různá, např. disky Western Digital bývají nastaveny na maximální výkon. Disky Seagate podporovaly AAM u starších modelů Baracuda IV, v současnosti už ne, snad kvůli nějaké patentové tahanici. Na webu jsem našel takovéhle vyjádření: "Seagate has decided that we will no longer support AAM. Our drives are extremely quiet while operating at the highest performance levels, so we believe the ability to switch between modes is unnecessary. We are also involved in patent litigation with Convolve and MIT. Although we believe the lawsuit is without merit, Convolve alleges that one of its patents, US Patent No. 6,314,473, covers AAM technology." Opět existují specializované utility od výrobců disků, jako třeba SeaAAM pro disky Seagate nebo Hitachi Feature Tool, který funguje i disky ostatních výrobců. Také můj program SMB umí nastavit úroveň AAM zavoláním funkce IDE_AAM(kanál,jednotka,úroveň) v debug konzoli. Obvykle se úroveň AAM nastavuje jako číslo 1-254. Čím větší číslo, tím je disk rychlejší a hlučnější. U některých disků lze úroveň AAM nastavovat až od 128. Zkoušel jsem si pohrát s AAM u svého WD400EB, ale nepoznal jsem mezi krajními hodnotami nějaký rozdíl a podle benchmarku dopadla přístupová doba úplně stejně, tak nevím jestli si ze mě dělá WD prdel. Každopádně hluk seeku mě netrápí zdaleka tolik jako vypískaná ložiska motoru, oproti tomu novému Seagate je to úděsnej kravál. Když WD pošlu spin-down, tak zůstane jen šumění vzduchu větráků...
Security
Výrobci disků také myslí na bezpečnost. Od verze ATA/ATAPI-3 je definovaná sada ATA příkazů pro nastavení a vypnutí hesla, úrovně zabezpečení, zamknutí a odemknutí jednotky a vymazání dat (např. pomocí nástroje ATA Tools). Systém umožňuje nastavit dvě úrovně hesla - user a master password (32 B) a dvě úrovně zabezpečení - high a maximum. Pokud nastavíme a aktivujeme uživatelské heslo, nelze po vypnutí a zapnutí na jednotku dále přistupovat. To se děje na úrovni blokování ATA příkazů, takže to nelze žádným softwarem obejít s vyjjímkou příkazu security unlock, který vyžaduje zaslání platného uživatelského hesla. Navíc se počítá každý neplatný pokus o odemknutí a když dosáhne určité hranice, zablokuje jednotku úplně dokud nedojde k dalšímu vypnutí/zapnutí. Pokud je nastaveno master password (s pomocí master password lze samozřejmě vypnout uživatelské heslo), záleží na režimu zabezpečení. V režimu high stačí pro odemknutí poslat security unlock a platné master password. V režimu maximum už nezbývá nic jiného než příkazy security erase prepare a security erase unit, které kompletně vymažou s heslem i obsah disku. Heslo je uloženo buď přímo na disku a nebo v nějakém EEPROM čipu na desce elektroniky, v takovém případě by to šlo třeba nějak obejít...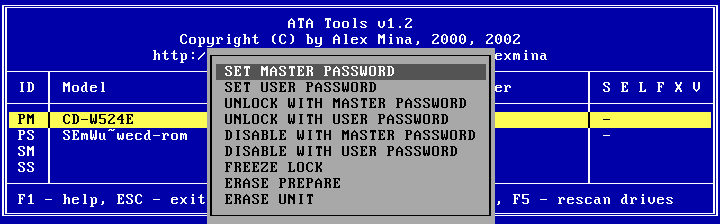
A další...
Pomocí příkazů specifikace ATA/ATAPI-7 lze nastavovat ještě řadu dalších zajímavých věcí, které zmíním už jen letmo. Některé disky podporují nastavení APM, kde je jedním bajtem nastavuje poměr výkon vs. spotřeba. Disky které APM nemají podporují alespoň několik power save režimů: idle, stand-by, a sleep. Při stand-by a sleep se obvykle vypíná motor jednotky. Další možnost je nastavení timeru, který po daném čase, pokud nebyl žádný přístup na disk, přepne jednotku do idle nebo stand-by režimu. čas lze nastavit v rozpětí 5s až asi 8hod.Dnešní disky disponují už poměrně velkou cache, např. ST3120026A má 8 MB. Jedním ATA příkazem lze tento buffer přepnout tak, aby se používal jen při čtení a ne při zápisu (aby nemohlo dojít ke ztrátě dat při náhlém vypnutí). Další příkaz flush chache provede okamžité zapsání obsahu bufferu na disk. Toto by měl nějakým způsobem obsluhovat operační systém.
Další zajímavostí je nastavení konfiguračních bitů, které překrývají feature bity vrácené příkazem identify device. Výrobce tak má možnost dodatečně povypínat některé funkce. Disk se pak tváří, jako kdyby tyto funkce nikdy neměl. Lze tak např. vypnout S.M.A.R.T., AAM, APM, některé UltraDMA módy a další. Příkazem device configuration restore se pak lze vrátit k původnímu nastavení. Zjišťoval jsem, jesi náhodou tímto způsobem není u nových Seagate vypnut AAM, ale bohužel ne.
ATA příkazů je opravdu celá řada, sám jsem jen poodhalil co všechno lze tímto způsobem provádět a o čem jsem předtím neměl ani potuchy. A tak nakonec můžu jen konstatovat že vím, že nic nevím ;-). Pokud by to někoho zajímalo do hloubky, tak tady je (ATA-7a, ATA-7b, ATA-7c). specifikace.
Pokud vás zajímají disky spíše z pohledu uživatele a správce serverů, doporučuju k přečtení článek Františka Ryšánka o nastavení a ladění výkonu diskového subsystému (RAID, cache, IO scheduler, atd.) v Linuxu.
6.7.2005 Přes všechny moderní technologie mě dnes večer potkala havárie pevného disku WD400EB jako blesk z čistého nebe. Zhruba po 2 hodinách normálního chodu na mě z ničeho nic vyskočila windowsí BSOD s tím, že nelze zapisovat na jednotku H:. Nejprve sem myslel, že se jen zaplnilo místo v TEMPu, tak jsem uložil práci jinam a preventivně restartoval. Po restartu jsem už neviděl 3 log. oddíly a na jednom nebyly vidět adresáře. Když jsem spustil utilitu DLGDIAG, tak při pokusu o spuštění testu se místo toho zobrazila tabulka S.M.A.R.T. atributů s varováním, že min. jeden klesl pod prahovou hodnotu (Raw Read Error Rate). Po vypnutí a zapnutí a novém pokusu o test jsem dostal hlášení, že disk obsahuje příliš mnoho chyb:
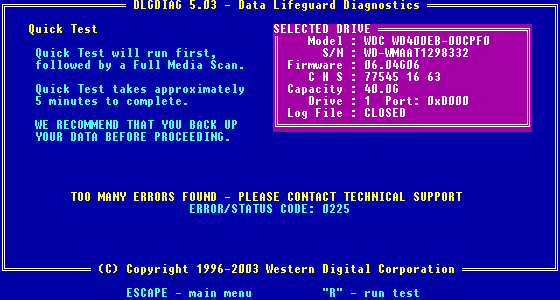
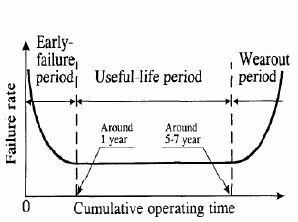
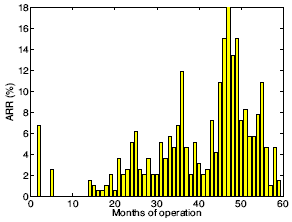
Ruční opravou partition tabulky se mi podařilo obnovit přístup na zmizelé log. oddíly a zachránit nějaká data. Další jsem měl zrovna náhodou před pár dny zálohované na jiném disku, takže jsem dohromady o nic nepřišel. Disku zřejmě odcházely ložiska, protože byl už hlučnější a další den měl i problémy s kolísáním otáček a dokonce zastavováním spindle motoru. BTW jak je vidět, je třeba brát údaj výrobce o MTBF (Mean Time Between Failures) = 500000 hodin (57 let) dost s rezervou, tento disk totiž vydržel jen 11165 hodin. Zažitá teorie předpokládá u disků závislost chybovosti na čase podle klasické vanové křivky (viz obrázek vlevo), kde po počáteční vyšší úmrtnosti následuje provozní období relativního klidu (zde by měla platit hodnota MTBF) a ke konci životnosti disku se chybovost opět začne zvyšovat. V praxi se ale ukázalo, že se disky vanovou křivkou až zas tak moc neřídí a chybovost začne narůstat už po poměrně krátké době od uvedení do provozu (viz obrázek vpravo). Tato data pochází z většího statistického souboru z reálného provozu, více se o tom můžete dočíst v dokumentu: Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? Zajímavá konkrétní statistická data a grafy o chybovosti disků zveřejňuje každý kvartál společnost Backblaze, která provozuje desetitisíce disků.
 |
 |
Bohužel BIOS mojí základní desky nepodporuje S.M.A.R.T. monitoring a ani operační systém Windows tyto informace není schopen využít k včasnému varování (světlou výjimkou je linuxový smartd, ale linux bootuju jen občas). Proto jsem si po této nepříjemné zkušenosti dal testování S.M.A.R.T. statusu přímo do autoexec.bat - s pomocí mojí utility SMB 1.18 (C:\DOS\smb.exe /dbg C:\DOS\smbsmart.txt) a jednoduchého skriptu:
SMBSMART.TXT: #find HPT37x controller ide_detect(4) #check S.M.A.R.T. status of primary and secondary IDE on channel 0 ide_smart_status(0,0) ide_smart_status(0,1) exit2.2.2013 Před 2 týdny se se mnou začal loučit další disk značky Western Digital, model WD5000ABYS RE2 500 GB SATA. Začalo to tím, že jeden večer při běžném brouzdání po netu (pod Windows XP) disk náhle vypnul motor a začal se cyklicky roztáčet a vypínat v asi 3-vteřinových intervalech. Hlavy přitom vydávaly podezřele hlasitý bzučivý zvuk. Windows zatuhly, takže jsem musel PC natvrdo restartovat a tím se disk nakopnul a běžel zas normálně. Okamžitě jsem zkontroloval S.M.A.R.T. status, ale nic podezřelého jsem tam neviděl. Spustil jsem znovu systém a nechal celý disk zkontrolovat - žádná chyba se nenašla. Napadlo mě, že by to mohl mít na svědomí i uvolněný napájecí konektor, zkusil jsem ho tedy znovu nasadit a nechal bočnici case jen lehce nasazenou. To samé se opakovalo ještě za dva dny. Sáhnul jsem do bedny, vytáhnul a zasunul napájecí konektor od disku a disk zase normálně naběhnul, dokonce i Windows XP se znovu rozběhly jako by se nic nestalo. Podle S.M.A.R.T. opět žádný problém. To už jsem dále nechtěl nechávat náhodě a začal disk zálohovat na externí USB RAID. Od té doby se disk choval normálně. Až dnes při migraci dat na nový disk jsem si všiml, že se ve S.M.A.R.T.u objevil jeden podezřelý (pending) sektor. To ještě neznamená žádné ohrožení dat, až ho FW disku vyhodnotí jako nespolehlivý, tak provede relokaci jiným rezervním sektorem a data zkopíruje. Nicméně to signalizuje, že je v disku něco špatně a postupně se bude pravděpodobně počet vadných sektorů zvyšovat, takže výměnu disku jsem naplánoval akorát v čas. Disk jsem zakoupil 30.11.2007 a od té doby běžel skoro každý den, tedy asi 5 let (necelé 2 roky čistého chodu). Na to, že se jedná o serverový disk pro 24/7 provoz bych čekal lepší výdrž. Záruka byla 3 roky. Jeho souputník Seagate Barracuda ST3120026A mi tu vrní už 8 let bez chybičky (a to občas dostával v šuplíku záhul přes 60°C, když jsem zapomněl zavřít bočnici a šuplíkem tak netáhnul vzduch). Zde je výpis S.M.A.R.T. atributů WD5000ABYS RE2:
S.M.A.R.T. data rev. 16; 17 valid attributes found, ckecksum: OK ---- ATTRIBUTE NAME ---- VALUE - WORST - THRS ---- RAW --- (* IniVal. ! PFail.) Raw Read Error Rate: 200 / 200 / 51 / 1 Spin-up Time: 186 / 163 / 21 / 5658 Start/Stop Count: 95 / 95 / 0 / 5279 Reallocated Sector Count: 200 / 200 / 140 / 0 Seek Error Rate: 100* / 253 / 51 / 0 Power-on Hours Count: 78 / 78 / 0 / 16367 (681.96 days) Spin-up Retry Count: 100* / 100* / 51 / 0 Calibration Retry Count: 100* / 100* / 51 / 0 Start/Stop Cycle Count: 95 / 95 / 0 / 5192 (7.61x/day) Power-off Retract Cycle: 199 / 199 / 0 / 1144 Move to L-Zone Cycle Cnt: 199 / 199 / 0 / 5257 Drive Temperature: 122 / 103 / 0 / 28 °C Reallocated Event Count: 200 / 200 / 0 / 0 Current Pending Sect.Cnt: 200 / 200 / 0 / 1 Off-line Scan Uncorr.Cnt: 200 / 200 / 0 / 0 UltraDMA CRC Error Rate: 200 / 200 / 0 / 0 Write Error Rate: 200 / 200 / 51 / 0 |
4.2.2013 Ještě než mi začal odcházet starý 500GB disk, měl jsem zrovna v plánu pořídit nový 128GB SSD Samsung 840 Pro a 1TB disk WD1003FBYX RE4 na SATA 3. O víkendu jsem disky úspěšně rozdělil a migroval stávající operační systémy a data. Z nového disku jsem se ale neradoval moc dlouho, při spuštění diagnostiky DLGDIAG 5.20 a pokusu o spuštění rychlého nebo úplného selftestu na mě vyskočila dosti podivná chybová hláška:
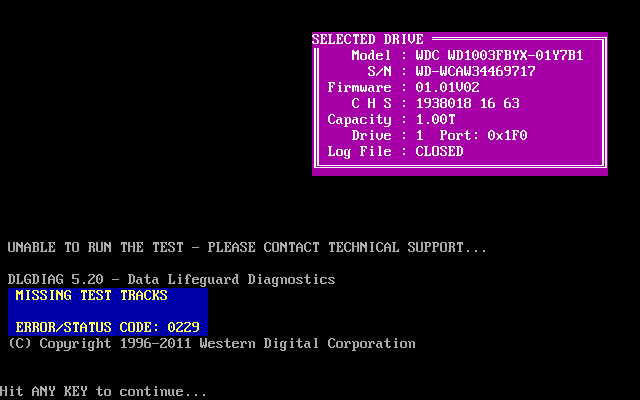
Avšak podle S.M.A.R.T.u je disk zcela zdravý, ani jsem nepozoroval poklesy výkonu nebo podezřelé akustické projevy. Spíše to vypadá na nějaké opomenutí ve výrobě, že tam prostě v závěrečné fázi zapomněli ty testovací stopy (oblast na začátku disku před uživatelskými daty) nějak vytvořit. Nebyla by vyloučená ani chyba/nekompatabilita testovací utility a firmware disku. Jelikož jsem někdy před rokem úplně stejný disk (včetně verze FW 01.01V02) kupoval do práce do serveru, zkusil jsem pustit DLGDIAG 5.20 i tam a disk žádnou chybu nehlásil (selftest se normálně spustil).
Pátral jsem tedy na Googlu, co ta chyba znamená, ale nenašel jsem žádné relevantní info, pouze jednoho stejně poškozeného zákazníka. Založil jsem tedy vlákno na WD Community fóru a zatím nikdo z WD nepodal vysvětlení, pouze od uživatele fzabkar jsem se dověděl o co asi tak jde:
Hard drives have a reserved System Area (SA) on the platters. The SA is also sometimes referred to as the negative cylinders. This area stores the bulk of the drive's firmware, SMART data, defect lists (G-list and P-list), plus manufacturing test logs.
I expect that there would also be test tracks reserved for read and write testing or calibration. Part of Data LifeGuard's diagnostic testing involves checking the read and write elements of each head. In order to test these components, I would think that the drive would need to write on a "scratch" area within the SA. Perhaps there was a manufacturing oversight that has rendered this area inaccessible?
Napsal jsem tedy e-mail na podporu WD a dostal druhý den stručnou odpověď:
Based on the information you provided and the results of the tests, we can determine the drive is defective and needs to be replaced. We have two warranty replacement options available: Advance RMA and Standard RMA...
OK, akorát co teď s datama na disku, nemám jinde tolik volného místa, navíc potřebuju mít PC v provozu.
11.2.2013 Koupil jsem si tedy v CZC další disk, na který jsem naklonoval data z původního a ten odnesl 12.2. na reklamaci. Doufám, že se to podaří vyřídit do 14 dnů, abych stihl nový disk vrátit. Samozřejmě jsem na něj taky pustil DLGDIAG 5.20 a chyba 0229 se objevila též. Sériové číslo je asi o 67000 vyšší, což by byla pěkně velké série, pokud číslujou po 1. Uvidíme, jak se to vyvrbí...
15.2.2013 podpora Western Digital otáčí o 180° a vinu místo disku háže na DOSovou verzi DLGDIAGu, disk je prý v pořádku. Co je mi to teď platné, když už je disk v reklamaci. Dnešní odpověď:
By suggestion of our development team, I suggested you to use the Data Lifeguard Diagnostic for Windows. It seems that this issue happens when testing using the DOS version. The issue has been already submitted in order to diagnose and recreate. You can rest assured that the drive is working properly and without any errors.
25.2.2013 mi vypršela 14-denní lhůta na vrácení zboží, takže mi nezbylo než zazálohovat "zapůjčený" disk na externí RAID pole a část nahrát na starý WD5000ABYS a doufat, že neklekne. Disk jsem dle dohody bez problémů vrátil a dostal peníze zpět.
1.3.2013 Jak se dalo očekávat, reklamace byla zamítnuta s tím, že je disk je prý v pořádku. Pustil jsem plný selftest, nakopíroval data zpět a budu doufat, že vydrží. Z technické podpory jsem se doposud nedozvěděl žádné bližší vyjádření ohledně DLGDIAGu. Na fóru se ozval jeden uživatel, že narazil na stejný problém u 2TB modelu řady Green WD20EARS-00MVWD0 s firmware verze 51.0AB51. Dále jsme zjistili, že starší verze DLGDIAG 5.04f (stejně jako verze pro Windows) chybu 0229 na těchto discích nehlásí.
7.3.2013 Poslední odpověď ze supportu WD:
We have passed this information to the development team in charge of your product. Please disregard the error message that you got since this was caused by the software and not an error from the hard drive itself.
Seagate Debug Console
18.3.2011 Elektronika nových pevných disků je stále sofistikovanější a najdeme zde zákaznické obvody s vysokou hustotou integrace, které obsahují nějaké procesorové jádro, např. ARM nebo MIPS a pod. Je to vlastně takový malý počítač v počítači na kterém běží proprietární firmware od výrobce disku. Větší složitost s sebou ale zákonitě nese větší pravděpodobnost výskytu chyb a ani firmware disků není výjimkou. O tom se mohli před časem na vlastní kůži přesvědčit majitelé některých disků Seagate Barracuda řady 7200.11. Chyba se opravovala dokonce několikrát a snad už je to v novém firmware definitivně vyřešeno. Problém nastával při překročení určitého počtu záznamů ve S.M.A.R.T. logu, kdy se při dalším zapnutí disk "uzamkl" a BIOS ho přestal detekovat. Data však zůstala neporušena a jak si ukážeme dále, lze takový disk znovu zprovoznit.Teď se na mě zrovna obrátil s prosbou jeden známý, zda-li bych se mu nepodíval na dva "tuhé" 320GB disky ST3500320AS. Když jsem kouknul na Internet, našel jsem spoustu lidí, kteří řešili stejný problém včetně návodů na oživení disků. Já jsem postupoval zhruba podle tohoto. Princip opravy je docela jednoduchý: terminálovým programem se připojíme na sériovou debugovací konzoli disku, zadáním pár stručných příkazů smažeme S.M.A.R.T. log a následně aktualizujeme firmware disku.
Pro komunikaci s okolím v takovýchto nouzových případech nebo pro účely ladění firmware mají disky Seagate vyvedenou sériovou linku přímo z řídicího procesoru na pinový konektor vedle datového a napájecího konektoru, viz následující zapojení:
EIDE Seagate Barracuda Diagnostic Serial Console pinout: ******************************************************** __________ __________________________ | | (GND) (GND) (Rx ) (GND) / \ | ::::IDE | | (+5V) (GND) (GND) (+12V) | |__________| (M/S) ( ? ) (Tx ) (32G) |__________________________| Rx/Tx : 3,3V CMOS levels, 9600 baud, 8, 1, N SATA Seagate Barracuda Diagnostic Serial Console pinout: ******************************************************** _____________ ________ | | | | | POWER | | SATA | ( Rx ) ( Tx ) (GND) (SATA 1.0/2.0) |_____________| |________| Rx/Tx : 2,8V CMOS levels, 38400 baud, 8, 1, N |
 |
Pro komunikaci lze použít libovolný terminálový program, masochisti mohou použít i Hyperterminál z Windows :) Po otevření portu s danými parametry: bitová rychlost 38400 baudů, 8 datových bitů, 1 stop bit, bez parity, bez řízení toku a po stisku klávesové kombinace CTRL+Z by se měl v terminálu objevit prompt ve tvaru "F3 T>" (poslední číslo nebo písmeno indikuje aktuální level) a případně další výpisy. Do shellu pak lze zadávat různé příkazy potvrzované entrem (bacha na case sensitivitu), viz seznam diagnostických příkazů. Většina příkazů funguje jen v určitém levelu (logická skupina příkazů týkající se konkrétního subsystému, např. level 4 = Servo Tracking Commands) a mezi levely se přechází příkazem /n, kde n je číslo 1 až 9 nebo písmeno T. Ale pozor, některé příkazy mohou disk nenávratně poškodit, takže nic pro lamy! O této funkci disků vím od Franty už asi 2 roky a teprve teď se mi to opravdu hodilo v praxi.
Můj konkrétní postup v případě léčení disků ST3500320AS vychází z návodu odkazovaného výše. Zde se věc kapánek komplikuje tím, že v tomto chybovém stavu BUSY je debugovací konzole zamčená, přesněji řečeno read-only (jsou vidět různé výpisy, ale na CTRL+Z nereaguje a nelze zadávat příkazy). K odemknutí konzole je potřeba provést trik spočívající v dočasném odpojení přívodů magnetických hlav disku od desky s elektronikou. V návodu se hovoří o zasouvání proužku izolantu mezi pérka konektoru hlav a elektroniku, ale mě stačilo jen povolit 3 Torx šroubky na levé straně destičky elektroniky (z pohledu na spodní stranu) a ono se to odpruží (případně lehce nadzvednout kraj plochým šroubovákem).
Takto připravený disk jsem normálně připojil do vypnutého PC včetně FTDI USB redukce a zapnul. BIOS ani Windows si disku nevšimly. Pustil jsem terminál a otevřel daný COM port. Po stisku CTRL+Z se mi objevil prompt "F3 T>" do kterého jsem postupně zadal příkazy: /2 (přístup na level 2), Z (vypnutí motoru - bylo slyšet, jak se motor vypíná, ukončeno hláškou "Spin Down Complete") a po zastavení jsem opatrně zašrouboval zpět ty 3 Torx šroubky, takže elektronika měla opět kontakt s hlavami. Následovaly další příkazy: U (zapnutí motoru, ukončeno hláškou "Spin Up Complete"), /1 (přístup na level 1), N1 (znovu-vytvoření S.M.A.R.T. sektoru) a /T (přístup zpět na level T). Pak jsem PC s diskem na chvilku vypnul a znovu zapnul a tentokráte už BIOS disk našel. Disk byl pod Windows zatím stále nepřístupný. Spustil jsem znovu terminál, připojil se na konzoli a po stisku CTRL+Z dokončil operaci příkazy: i4,1,22 (smazání G-listu) a m0,2,2,,,,,22 (naformátování uživatelské oddílu [vaše data to nijak nepoškodí], které trvalo asi půl minuty, ukončeno hláškou "User Partition Format Successful - Elapsed Time 0 mins 30 secs"). Celý průběh je shrnut v tomto logu:
LED:000000CC FAddr:0024A051 LED:000000CC FAddr:0024A051 LED:000000CC FAddr:0024A051 F3 T> F3 T>/2 F3 2>Z Spin Down Complete Elapsed Time 0.141 msecs # přišroubování desky s elektronikou F3 2>U Spin Up Complete Elapsed Time 6.638 secs F3 2>/1 F3 1>N1 F3 1>/T # pokračování po power off/on cyklu F3 T>i4,1,22 F3 T>m0,2,2,,,,,22 Max Wr Retries = 00, Max Rd Retries = 00, Max ECC T-Level = 14, Max Certify Rewrite Retries = 00C8 User Partition Format 5% complete, Zone 00, Pass 00, LBA 00008DED, ErrCode 00000080, Elapsed Time 0 mins 30 secs User Partition Format Successful - Elapsed Time 0 mins 30 secs F3 T> |
Nyní by měl být disk po dalším startu už přístupný. Před dalším používáním je však nanejvýš vhodné aktualizovat na nejnovější firmware, aby se chyba nemohla opakovat. Při aktualizaci jsem měl z neznámého důvodu problém s tím, že disk byl sice utilitou seaenum.exe korektně rozpoznán, ale flasher fdl464.exe (voláno z flash.bat) mi hlásil, že nemá žádný firmware pro můj disk, přestože typ seděl a soubor s firmware sd1a2d.lod tam byl. Nakonec jsem ho ale znásilnil ručně sadou parametrů fdl464.exe -m Moose -f sd1a2d.lod -s -x -b -v -a 20.
C:\STFWUPD>seaenum.exe SeaEnum v1.04EH Copyright 2001-2009 Seagate Technology LLC, All Rights Reserved Scanning for devices... Scanning for devices on Generic PCI ATA... Scanning for devices on Generic PCI ATA... Detected 2 devices Device scan complete Device Model SN FW Controller 0 ST3500418AS 5VMEQ20C HP35 Generic PCI ATA 1 ST3500320AS 9QM6BASK SD15 Generic PCI ATA C:\STFWUPD>fdl464.exe -m Moose -f sd1a2d.lod -s -x -b -v -a 20 Model ST3500320AS SN 9QM6BASK FW SD15 on Generic PCI ATA Bus 0 Device 1 Sending Binary Downloads Model ST3500320AS SN 9QM6BASK FW SD1A Model ST3500418AS SN 5VMEQ20C FW HP35 on Generic PCI ATA Bus 0 Device 0 Sending Binary Downloads Model ST3500418AS SN 5VMEQ20C FW HP35 C:\STFWUPD>seaenum.exe SeaEnum v1.04EH Copyright 2001-2009 Seagate Technology LLC, All Rights Reserved Scanning for devices... Scanning for devices on Generic PCI ATA... Scanning for devices on Generic PCI ATA... Detected 2 devices Device scan complete Device Model SN FW Controller 0 ST3500418AS 5VMEQ20C HP35 Generic PCI ATA 1 ST3500320AS 9QM6BASK SD1A Generic PCI ATA |
Z výpisu je vidět, že původní verze firmware SD15 byla updatována na verzi SD1A. Přeflashování firmware chvíli trvá, doporučuji proto pracovat na PC se zálohovaným napájením UPSkou.
Po dalším restartu Windows normálně rozeznaly disk a oddíly na něm. Souborový systém vypadal neporušeně, náhodně otevřené soubory taky OK. Stejným postupem jsem úspěšně opravil i druhý disk. Zajímalo by mě, zda-li nějaké takové debugovací rozhraní mají i disky Western Digital a případně další výrobci. Později jsem našel utilitu STComTools, která komunikuje s disky Seagte přes debug konzoli. Na té stránce je i řada utilit a FW pro ostatní disky.
Pokus o opravu HDD Seagate Barracuda 7200.7 ST380011A
11.3.2018 mi z nenadání odešel HDD Seagate Barracuda 7200.7 ST380011A (80 GB PATA), který jsem měl zrovna připojený k PC přes externí USB rámeček ICY BOX IB-351U-B a několik hodin na něj kopíroval nějaká data. Najednou disk přestal reagovat, zastavil se a pokojem se rozhostil notoricky známý smrádek spálených polovodičů. Otočil jsem se a viděl, jak z USB rámečku stoupá trocha modrošedého dýmu. Po odpojení napájení a vyndání disku jsem ihned našel na elektronice disku poškozené součástky z kterých magický dým unikl a staly se tak nefunkční. Odnesl to jeden P-FET FDFS2P102A (FETKY kombo s integrovanou Schottkyho diodou) a 2 odpory 1 Ω paralelně, které byly zapojené do série s FETem a cívkou, pod nimiž pěkně zuhelnatěl plošňák. Multimetrem jsem propípal desku a nakreslil schéma zapojení toho spínaného zdroje, který vytváří nějaké pomocné napětí jdoucí na konektor hlav disku J1, viz níže. Napájecí zdroj USB rámečku byl dost teplý, nicméně změřená napětí obou napájecích větví 5 V a 12 V byla OK.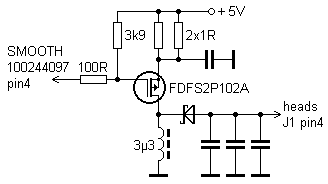 |
Odpory a FET jsem vyměnil z šuplíkových zásob za IRF7326, ale po zapnutí disku se vůbec neroztočil motor. Zjistil jsem, že odešel (bez dýmových efektů) i motor driver SMOOTH 100244097, který FET přímo řídí, takže po své smrti nechal FET sepnutý a ten se i s odporama upálil. Stejný motor driver jsem nikde v zásobách, ani na jiném disku nenašel, ale při nejhorším se dá koupit u Číňanů. BTW o pár let později jsem zjistil, jak snadné je takový motor driver odprásknout, když jsem si hrál s vadným diskem Samsung, který jsem za chodu celý rozšrouboval a různě s ním blbnul. Když jsem pak povolil poslední šroubek od elektroniky, který držel přítlak kontakntích pérek motorku, tak z čipu motor driveru od TI okamžitě vyšlehnul asi centimetrový plamínek a bylo po prdeli...
 |
Zkusil jsem tedy přehodit desku elektroniky z jiného podobného disku ST380013A (též 80 GB), motor se rozběhl, ale disk se nedetekoval a periodicky v něm cvakala hlava (disk jsem otevřel až později). Požádal jsem o pomoc na fórech ostatní, jestli někdo nemá přesně stejný typ disku. S jedním maníkem jsem se pak sešel na radioburze, kde jsme zkusili přehodit desky elektroniky ze 2 disků, ale nechytlo se to. Také mě překvapilo, že stejný typ disku se vyráběl s několika různými verzemi elektroniky, kde byly jiné typy motor driveru a řídícího procesoru. Nabyl jsem domněnky, že v procesoru může být integrovaná nějaká NV paměť s konfiguračními/kalibračními daty specifickými pro konkrétní disk a že je tedy deska elektroniky nezaměnitelná.
 |
 |
 |
| PCB1 (moje) | PCB2 (donor) | SMOOTH 100244097 |
Pak se mi ozval další dobrovolník a nabídl mi na výměnu postradatelný disk ST380011A se stejnou deskou elektroniky, se stejným motor driverem, ale jiným procesorem AGERE 4490D6 (na mé desce je procesor ST 100274360). Prohodil jsem desku a pořád nic. Přepájel jsem tedy motor driver na svou desku, ale ani tak se to nechytlo. Když jsem svou desku namontoval do darovaného disku, tak ten s ní normálně fungoval, takže jsem si ověřil, že moje elektronika je skutečně funkční. Objevila se další domněnka, že mohlo dojít k poškození zesilovače hlav (čip uvnitř disku pevně spojený s ramínkem hlav). Takže jako poslední možnost mi zbylo pokusit se o výměnu plotny (naštěstí je v disku jen jedna, jinak nevím, jak bych řešil vzájemné zarovnání více ploten vůči sobě). Podle tohoto videa to zas není taková věda.
 |
 |
 |
 |
| demontáž magnetu | detail hlav | odstavení hlav | vyjmutí plotny |
Disk jsem otevřel (jeden torx šroubek se nachází pod samolepkou), prohlídl plotnu a hlavy, ale nevšiml jsem si žádného mechanického poškození. Pro uvolnění plotny je potřeba nejprve odšroubovat jeden šroub horního magnetu a ten vyjmout (drží přicuclý poměrně velkou silou). Tím se odstraní dorazy ramínka hlav, takže je možné s ním vyjet z kraje plotny. Mezi hlavy jsem strčil párátko, aby se mi nepřiplácly k sobě a nepoškodily o kraj plotny. Ramínko hlav je potřeba něčím zajistit, aby se nevracelo zpátky. Pak už jen stačí odšroubovat 6 šroubků na motoru, vyjmout prstenec přitlačující plotnu a tu následně opatrně vytáhnout. Při montáži pak zase pozpátku nejprve nasadit plotnu a prstenec na unašeč motoru a přišroubovat, uvolnit ramínko hlav a opatrně s ním najet na plotny, přicvaknout horní díl magnetu a zajistit ho 1 šroubkem. Po zapnutí jsem očekával, že se disk konečně chytí, ale místo toho hlava dojela asi do 1/3 plotny a začala vydávat podivné škvrčení/pištění (přestože mechanicky při vypnutém disku bylo ramínko pohyblivé bez jakéhokoliv drhnutí), občas sebou i škubla ke kraji, ale disk se nedetekoval. Jako by nemohl najít správnou stopu s konfiguračními daty. Jak jsem později zjistil, divný pištivý zvuk zmizí, pokud se zatlačí shora na ložisko hlav nebo se přišroubuje dekl disku tím šroubkem, který prochází osou ložiska hlav (ten pod samolepkou). Má to asi co dočinění s nějakým zarovnáním hlav, protože když se tento šroubek povolí u zdravého disku, tak má najednou taky problém naběhnout a piští.
Když jsem pak ramínkem různě cvičil rukou a nutil ho číst z kraje, tak po mnoha pokusech se mi nakonec podařilo, že se disk detekoval a normálně se načetl souborový systém i adresářová struktura a dokonce některé soubory byly čitelné. Disk se však při čtení choval divně a nakonec skončil chybou čtení a dál už nereagoval. Po vypnutí/zapnutí se zas nechtěl detekovat. Povedlo se mi ho pak ještě jednou probrat z komatu mrazákovou metodou - dal jsem ho v uzavíratelném plastovém pytlíku asi na 2 hodiny do mrazáku a pak se dokonce po chvilce hrabání detekoval bez pomoci a šlo z něj zas trochu číst. Občas při čtení pomohlo jemně prstem přitlačit ramínko k povrchu. Prošel jsem obsah disku a zjistil, že tam zas tak nic nenahraditelného není, něco málo jsem i zkopíroval a s klidným svědomím ho zlikvidoval. Desku elektroniky si nechám, kdyby někdo náhodou potřeboval...
2.1.2021 Co se týče záměnnosti různých desek elektroniky a ukládání kalibračních údajů disku, zřejmě záleží na konkrétním modelu, jak je to řešené, viz též debata na bastlírně. U moderních HDD bývá na desce elektroniky sériová SPI flash, kde je uložen FW a nějaká specifická kalibrační data. Sešly se mi tady 2 úplně stejné 2TB disky Seagate ST2000DM001 s FW CC25. Zkusil jsem tedy vzájemně prohodit destičku elektroniky. Oba disky se sice roztočily a identifikovaly, ale ani jeden nefungoval. Identifikace proběhla i když jsem elektroniku odpojil od mechaniky. Na jedné desce byla 1MB SPI NOR FlashROM paměť ON Semiconductor LE25S81MC a na druhé Winbond W25Q80BW na 1,8 V. Podporu těchto pamětí jsem přidal do nové verze SPIPGM 2.31. Flešky jsem odpájel horkovzduchem, přečetl data a porovnal - celkem 54525 diferencí v různých částech paměti, to je docela hodně. Čitelných řetězců tam moc nebylo. Strukturu obsahu paměti neznám, nevím jestli se tím už někdo zabýval. Používají se i procesory s vnitřní NV pamětí.
15.5.2022 Dostal se mi do ruky na otestování další 2TB disk Seagate ST2000DM001 s FW CC24, který je poškozený, detekuje se až po delší pauze nejdou z něj číst data ani S.M.A.R.T. status. I zde jsem ze zvědavosti zkusil prohodit elektroniku, ale tento disk ji má fyzicky dost odlišnou - PCB je větší obdélníkový, upevněný 6 šroubky místo 5 a s jiným rozložením součástek. Celkem nepřekvapivě po prohození obou PCB nefungoval ani 1 disk (hlásily se, ale nešlo číst data) a když jsem prohodil i SPI flashky, tak se diskům ani neroztočily motory. Poškozený disk jsem zkusil schladit v mrazáku a následně se mi z něj podařilo přečíst alespoň MBR a pár dalších sektorů, ale při dalším čtení vytuhnul. Takže jsem aspoň ověřil, že elektronika je funkční a chyba je někde na plotnách nebo hlavách a s tím nic nesvedu.
Pokus o opravu HDD Seagate Barracuda 7200.8 ST3200826AS
3.1.2021 Z ničeho nic mi tu odešel jeden starší 200GB SATA disk Seagate Barracuda 7200.8 ST3200826AS, který se přestal identifikovat. Disk se přitom normálně roztočí a pak je pravidelně cca každých 8 s slabě slyšet krátké pohnutí hlav. Na disk jsem přitom před týdnem instaloval Windows a nějaké programy na zkoušku, kontroloval jsem i S.M.A.R.T. a žádné relokované nebo pending sektory na něm nebyly. Zkoušel jsem mrazákovou metodu a nepomohlo to. Na desce elektroniky je 64kB sériová SPI NOR FlashROM paměť SST25VF512 na 3,3 V. Zkusil jsem ji odpájet horkovzduchem a několikanásobně přečíst pomocí SPIPGM při různém nastavení napájecího napětí, ale paměť dávala konzistentní obsah až do 1,8 V, takže v tom problém nebyl. Pro jistotu jsem ji smazal a znovu naprogramoval.Připojil jsem se tedy ke 4-pinovému 3,3V UART konektoru vedle SATA portu disku (viz výše) na debug konzoli 9600 baud. Po zapnutí disku se FW ohlásil, avšak v některých případech nějakou dobu opakoval dokola "(S)ATA", pak s mi stisku CTRL+Z podařilo dostat prompt "T>". Při pokusu o znovu-vytvoření S.M.A.R.T. sektoru zadáním příkazu N1 disk něco dělal ale vypisoval při tom několikrát chybu "AutoRd Err 43". Na některé příkazy, které by měly normálně fungovat, disk reagoval chybou "Command Inactive - No VALID Cert Code Detected".
4096k x 16 buffer detected
TONKA - 1_Disk M-27 03-30-05 11:42
Head Mask FFFF - Switch to full int.
Spin Ready
3.03 06-21-05 17:16
(S)ATA(S)ATA(S)ATA...
^Z
T>
...
AutoRd Err 43 at ffffffff.01.0000
|
Domnívám se, že se z disku nepodařilo načíst všechny moduly firmware, protože došlo třeba nějakou mechanickou chybou k poškození těchto servisních stop. Když jsem desku elektroniky úplně odpojil od disku, tak naběhl pouze základní FW z flešky s promptem "F>" a velmi omezenou sadou příkazů, takže něco se z disku přece jen dařilo načíst, takže hlavy a jejich signálová cesta by měly být v pořádku. Zkoušel jsem s diskem také komunikovat pomocí programu ST Repair Tool 2013-5-10, kde se mi dařilo posílat jednodušší příkazy, ale třeba příkazy na přečtení SPI FlashROM nebo servisních stop mi nefungovaly, UART se asi přepnul na nějakou jinou rychlost, vypsalo to trochu rozsypaného čaje a program přestal s diskem komunikovat, občas jsem musel jeho proces natvrdo sestřelit. Ani jsem nenašel dump servisních stop ze stejného typu disku, které bych tam mohl nahrát.
Nakonec se mi podařilo při neopatrné manipulací s deskou elektroniky za běhu na ní odpálit nějaký miniaturní spínaný měnič a nejspíš taky motor driver a deska přestala po UARTu komunikovat, takže asi vymalováno. Mám akorát o něco novější disky Seagate Barracuda 7200.9 ST3160812AS, které mají mechanicky kompatabilní, avšak osazením částečně jinou desku elektroniky a používají novější firmware TONKA2. S touto elektronikou se disk roztočil, ale nenačetl žádný modul z disku a zůstal v "F>" promptu. Disk si zatím nechám, kdyby mě třeba ještě něco napadlo...
Jaký je rozdíl mezi disky pro desktop a Raid Edition?
Na několika různých fórech jsem narazil na informaci, že prý serverové disky Western Digital Raid Edition nejsou vhodné do desktopu na provoz jako single. Přitom jejich parametry by se jistě využily i ve výkonných pracovních stanicích - vyšší výkon, provoz 24/7 při plné zátěži, patrně robustnější mechanické provedení, 1200000 MTBF, 5-letá záruka. V čem je tedy problém? Patrně pouze v nastavení firmware, kde je u RE disků aktivovaná funkce TLER (Time Limited Error Recovery). V případě, že se na disku vyskytne chyba, snaží se firmware přečíst a relokovat poškozené sektory, což může na desktopovém disku trvat až 2 minuty. To je v pořádku, protože nechceme přijít o data. U vytíženého serveru, kde se standardně používají RAID pole, je naopak prodlužování smrtelné agónie disku nežádoucí a ztráta dat zde nehrozí. Proto se Raid Edition disk pokouší o nápravu pouze 7 - 15 vteřin a pak se odpojí. Obsluha je upozorněna na chybu a následně vymění šuplík s diskem za nový. Při použití Raid Edition disku v single režimu budeme nejspíš chtít TLER prodloužit nebo úplně vypnout. K tomuto účelu slouží nepříliš známá utilita WDTLER 1.03 pro DOS. Součástí balíčku jsou i 3 dávkové soubory tlerscan.bat, tler-off.bat a tler-on.bat pro snazší ovládání. V případě mých disků WD5000ABYS RE2 a WD1003FBYX RE4 byla doba TLER nastavena na 7 s a tak jsem TLER vypnul.
C:\WDTLER>tlerscan.bat WDTLER Version 1.03 Copyright (C) 2004-2006 Western Digital Corporation Western Digital Time Limit Error Recovery Utility Model: WDC WD5000ABYS-01TNA0 Serial Number: WD-WCAPW5536791 Read TLER time is 7.000 seconds. Write TLER time is 7.000 seconds. Model: WDC WD1003FBYX-01Y7B1 Serial Number: WD-WCAW34469717 Read TLER time is 7.000 seconds. Write TLER time is 7.000 seconds. C:\WDTLER>tler-off.bat WDTLER Version 1.03 Copyright (C) 2004-2006 Western Digital Corporation Western Digital Time Limit Error Recovery Utility Model: WDC WD5000ABYS-01TNA0 Serial Number: WD-WCAPW5536791 Read TLER is disabled. Write TLER is disabled. Model: WDC WD1003FBYX-01Y7B1 Serial Number: WD-WCAW34469717 Read TLER is disabled. Write TLER is disabled. |
Také by se vám mohla hodit DOSová utilita WDIDLE3 1.05 nebo idle3-tools pro Linux, která nastavuje idle3 časovač - doba po které disk při nečinnosti zaparkuje hlavy, což způsobuje nepříjemné časové prodlevy při požadavku na data a nadměrně zvyšuje opotřebení. Prý vydrží řádově statisíce cyklů, ze S.M.A.R.T.u lze přečíst jako atribut 193 - "Move to L-Zone Cycle Count". Prodlevu je možno nastavit v rozsahu 8 - 25,5 s u starších disků resp. 8 - 300 s u novějších disků nebo tuto funkci úplně vypnout.
Průlom limitu 2 TB
Kapacita pevných disků stále roste a nedávno byl překročen další limit 2 TB. Běžně dnes můžeme koupit např. 3TB disk Seagate Barracuda ST33000651AS. Nyní se objevily disky o kapacitě až 8 TB, které používají novou technologii zhuštěného zápisu SMR (Shingled Magnetic Recording), kdy se datové stopy při zápisu částečně překrývají. Čtecí hlava (narozdíl od zápisové) může být menší, takže užší stopy bez problému přečte. Data se však smí zapisovat jen sekvenčně, aby nedošlo k přepsání předchozích stop (náhodný přístup pak musí vyřešit firmware disku). Hustota dat u 8TB disku dosahuje cca 2000 bitů na 1 µm2, tedy 1 bit si lze představit jako čtvereček 22 x 22 nm.V případě 2TB limitu se však nejedná o limit na straně disku či řadiče (adresace LBA48 nám vystačí ještě na hodně dlouho), ale omezení BIOSu a starších operačních systémů. Problém je v tabulce rozdělení disků, která sídlí v MBR (Master Boot Record). Struktura MBR byla definovaná před desítkami let jako součást standardu IBM PC na tehdejší dobu poměrně velkoryse. Umožňuje definovat až 4 primární oddíly, každý záznam oddílu má vyhrazeno 16 Byte, kde jsou uloženy: 1 Byte status, 1 Byte typ souborového systému, 2x 3 Byte CHS adresa prvního a posledního sektoru oddílu a zbylo nám tam 2x 4 Byte pro LBA adresu prvního sektoru a počet sektorů v oddílu. Tzn. velikost oddílu může být max. 232*512 = 2199023255552 B (2 TB) a začátek oddílu pod hranicí 2 TB. Při startu PC načte BIOS z disku MBR do RAM a předá mu řízení. Jednoduchý kód MBR se podívá do tabulky rozdělení disků a vybere záznam, který je ve status Byte označen jako aktivní, načte z něj CHS nebo LBA adresu počátečního sektoru oddílu (boot sektor operačního systému), načte jej do RAM a spustí (ten pak zavede OS). Z toho plyne, že nelze startovat OS umístěné za hranicí 2 TB. Další omezení je, že 32-bitové Windows počítají interně s 32-bitovou LBA adresou, takže druhý oddíl, který by začínal těsně pod 2TB hranicí, stejně nebudou moci korektně používat. V 64-bitových Windows 7 to však možné je.
Kdyby v MBR zbyly nějaké rezervované bajty, bylo by možno LBA adresu a velikost rozšířit. Bylo by teoreticky možné využít i ony 2x 3 Byty pro CHS, neboť většina moderních OS pracuje s LBA adresací. Ale to by zas zmátlo různé diskové utility a mohlo by dojít ke ztrátě dat. Další možností by bylo zvětšení velikosti sektoru z 512 B na např. 2 nebo 4 kB, jenže opět spousta existujících programů počítá jen s 512 B, což by znamenalo zase problémy. Proto došlo na radikální řešení, které definuje zcela novou tabulku rozdělení disku, tzv. GPT (GUID Partition Table). Další info zde a zde.
HDD firmware hacking
Jak už jsem zmiňoval výše, HW i FW disků se s vývojem neustále zrychluje a zesložiťuje, což znamená také vyšší potenciál pro různé hacky. Jeden takový pěkný FW hack prezentoval v roce 2013 Sprite na konferenci OHM2013. Zjistil, že jeho disk od Western Digital obsahuje řadič Marvell 88i9146 se 2 rychlými jádry ARM Feroceon (jedno jádro řeší zpracování signálů z hlav a druhé komunikaci po SATA a správu cache paměti) a pomocným jádrem Cortex-M3 (jeho funkce nebyla objasněna), který má k dispozici 64 MB DDR SDRAM a FW je uložený v SPI FlashROM + záložní verze nahraná na plotnách. Na desku elektroniky disku se přes testpointy připojil k JTAG portu a pomocí programu OpenOCD mohl číst a modifikovat obsah paměti za běhu. Přidáním pár instrukcí upravil kód FW v RAM tak, že při čtení dat z disku modifikoval data v cache bufferu, aby každý přečtený sektor obsahoval v prvních 4 Bytech konstantu 12345678h. Dále přidal blok vlastního kódu do stávajícího FW ve FlashROM, který se spustil jako první a hooknul důležité funkce. S využitím zdrojového kódu idle3-tools pro Linux napsal i vlastní flashovací utilitu. Jeho upravený FW modifikoval za běhu při čtení linuxový soubor /etc/shadow, kde modifikoval hashované heslo roota na "test123". Tím se nabízí velmi pestrá škála využití a zneužití takových hacků, např. logování citlivých dat do skrytých sektorů v servisní oblasti (ta může mít klidně stovky MB), či opakovaná infekce souborů operačního systému. Pikantní na tom je to, že takovou záškodnickou činnost lze jen obtížně detekovat antiviry, natož mallware odstranit (jedině přes JTAG či HW programátor).Po aféře Edwarda Snowdena, kdy vypluly na povrch tajné informace o šmíráckých schopnostech americké NSA a jejích hackerů Equation Group, se ukázalo, že takovéto FW hacky používali už minimálně od roku 2010 jako součást velmi sofistikované mallware paltformy EquationDrug (vyvíjené v letech 2002 - 2013, později nahrazené nástupcem GrayFish). Jeden z modulů byl schopen přeflashovat FW disku infikovanou verzí staženou z C&C serveru a podporoval disky všech hlavních výrobců (Western Digital, Maxtor, Samsung, IBM, Micron, Toshiba a Seagate). Tento nástroj byl velmi pečlivě cílený na důležité strategické cíle (i mimo dosah Internetu). Aby nedošlo snadno k odhalení, byla potenciální oběť nejprve infikována pomocí DoubleFantasy (třeba přes nějaký zero-day exploit ve webovém prohlížeči) a teprve pokud byla vyhodnocena jako zajímavá, tak se do ní stáhnul a nainstaloval EquationDrug, jinak mohl po sobě zamést stopy. Podle analýzy Kaspersky lab byl flashovací modul nalezen pouze na 5 z 500 zkoumaných obětí, takže je velmi nepravděpodobné, že by se s ním běžný uživatel setkal. To se ovšem může po různých únicích takovýchto nástrojů na veřejnost změnit...